








Large language model (LLM)-based software engineering (SWE-)agents have recently demonstrated remarkable progress on realistic software engineering tasks such as code review, bug fixing, and repository-level reasoning. Most SWE-agents start from a fresh state for a given problem, which limits their understanding of the more complex structure of large software systems, such as inter-module dependencies, call hierarchies, build configurations, etc. A lot of progress has been made through carefully designed prompts and action spaces for LLM agents. However, agents can still struggle when facing more complex problems, in particular, when the agent chooses a wrong solution path for the problem.
This limitation reflects a broader challenge in agentic learning: how to enable agents to refine their policy to better adapt to the environment, without relying on external supervision or retraining. Inspired by recent trends in self-improvement, trajectory distillation, and self-reflective reasoning—as explored in works such as Reflexion [Shinn et al., 2023], Self-Refine [Madaan et al., 2024], LATS [Zhou et al., 2024], and ReAct-style [Yao et al., 2022] trajectory refinement—we propose an approach where the agent learns to induce better plans directly from its own experience on challenging tasks.
Instead of starting with a fresh state for a given problem, the agent is allowed to first explore and follow its own policy. The agent then uses its past experience to induce an abstractive plan, and thereby influence its policy on the problem. Concretely, its initial trajectory through the environment serves both as (1) a record of its evolving understanding and (2) a source of grounded feedback for plan improvement. This process can be viewed as a form of self-imitation learning or training-free on-policy adaptation, where the policy (planning module) improves through reflection rather than gradient-based updates (e.g., tuning model parameters

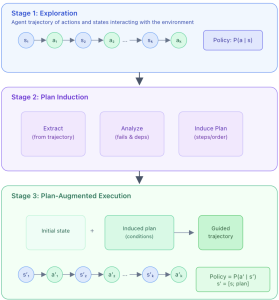
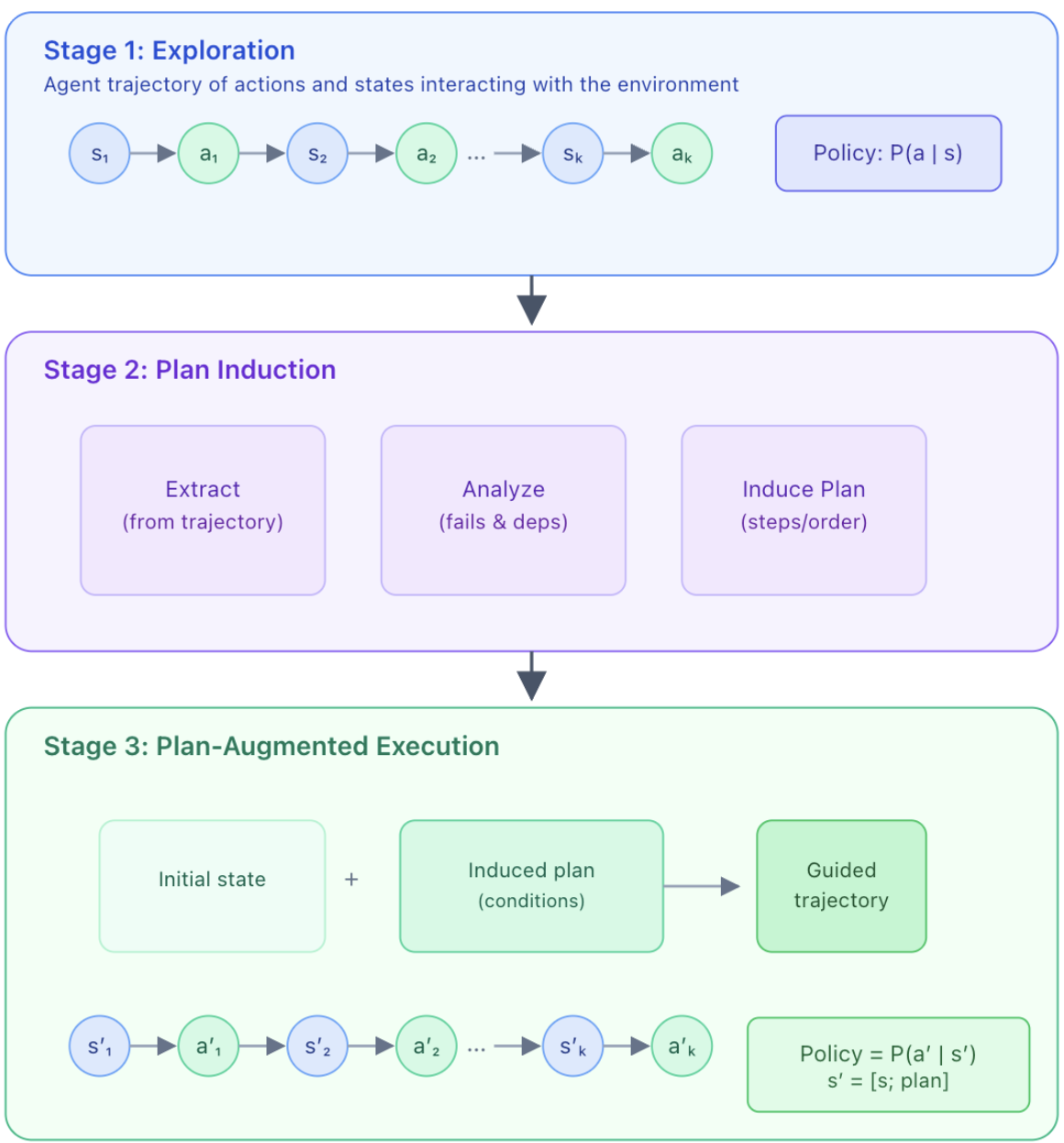
Method: Plan-Induction from Self-Experience
Our method—Self-Abstraction from Grounded Experience for plan-guided policy refinement (SAGE) follows a multi agent framework. The method can be viewed to have three stages.
Stage 1: Exploration and Trajectory Generation
The goal of this stage is to create experience in the environment so that it can be utilized later for the agent to refine its policy. More specifically
- The agent is deployed into the target environment with the specified goal
- The agent follows its current policy to complete the task
- The roll out trajectory (i.e. action, observation tuples) are then saved upon task completion
Stage 2: Plan Induction
In problem solving, choosing the right approach is often critical to the final result. Therefore, in this stage we let another agent infer the high level plan (approach) based on the experience obtained in stage 1. In more detail
- An plan induction agent is asked to infer the latent plan from the roll out trajectory
- The same agent is then asked to analyze and identify potential improvements can be made based on the target problem and the induced plan
- Finally, a newly proposed plan for the given problem is produced by the agent
Stage 3: Plan-Augmented Execution
In this stage, we provide the original agents the newly obtained plan from stage 2 so that it can shape a better policy for the given problem. The plan can also be viewed as a condensed memory from the previous attempt.
- The original agent is re-instantiated with the induced abstractive plan embedded in its context.
- The plan acts helps to reshape the agent’s policy for the given problem
Conceptually, this corresponds to meta-reasoning through self-play, or “learning to plan” by interpreting one’s own behavior—a lightweight analogue of policy improvement in reinforcement learning, but fully realized through language-based introspection.
Experiments
To validate the proposed approach, we performed experiments on the SWE-bench Verified dataset with various models, including GPT-5-mini, GPT-5, Gemini-2.5-pro, Claude Sonnet 4 and Claude Sonnet 4.5. We built the agent on top of mini-swe-agent [Yang et al., 2024], a simple agent framework with bash-only actions.
Fig. 1 shows the self-experience induced plan consistently improves performance as compared to their baseline.

Prior work [Zheng, et al., 2023; Panickssery, et al., 2024] on LLM judge shows that LLMs prefer their own generations. Plan induction shares similarities with using LLM-as-a-judge as it requires reviewing and evaluating trajectories sampled from the policy. When the plan-induction model is the same as the policy model, i.e. same LLM, it is possible that such self-bias leads to a biased assessment and thus suboptimal feedback. To investigate the impact of self-assessment, we perform experiments that vary both the agent backends (i.e. policy models) and the plan induction models.
| Policy Model | Plan Induction Model | Resolved (%) |
| GPT-5 (high) | GPT-5 (high) | 68.6 |
| GPT-5 (high) | Claude Sonnet 4.5 | 66.8 |
| GPT-5 (high) | Gemini-2.5-pro | 68.8 |
| Claude Sonnet 4 | Claude Sonnet 4 | 64.0 |
| Claude Sonnet 4 | GPT-5 (high) | 68.8 |
| Claude Sonnet 4.5 | Claude Sonnet 4.5 | 72.4 |
| Claude Sonnet 4.5 | GPT-5 (high) | 73.2 |
As shown in Table 1, there is no clear trend indicating that plan induction bias, towards trajectories sampled from the same LLM as the planner, leads to a difference in performance. Overall, Claude models seem to benefit more from other model induced plans. GPT-5 benefits from using the same planner LLM, though all agents still outperforms their respective baselines.
LLM Judge As Ensemble
Different agents tend to excel on different subsets of issues, so we adopt a simple ensemble strategy that uses LLM-as-a-judge to capitalize on this diversity. Concretely, we first gather a pool of candidate patches produced by heterogeneous agents (see Table 1). We then prompt an LLM to examine these candidates comparatively, assessing for each one whether it resolves the PR issue and whether it adequately covers potential edge cases. Based on these analyses, the LLM makes a final selection among the candidates. This procedure is lightweight, adding only modest overhead, yet it significantly improves the quality of the chosen patch. Notably, while any single agent may require a large number of LLM calls to generate a git patch, the ensemble judge makes just one call to select among completed candidates. In our experiments, this approach raises performance to 74.6; see Figure 2.

Evaluation Protocol
We evaluated our agent framework using the official SWE-bench evaluation harness package on 500 instances from the SWE-bench Verified dataset. During evaluation, we identified several gold patch validation issues in the official dataset that could lead to false negatives. To minimize their impact, we used the same instances from the SWE-bench dataset that reflect recent fixes—for example, astropy__astropy-7606 now removes a non-existent test case. We also addressed remaining gold patch failures, including compatibility issues in astropy__astropy-{8707,8872} (caused deprecated package usage) by updating the test_patch field to use modernized setup methods (fix reference). For the psf__requests-{1724,1766,1921,2317} instances, which intermittently failed due to 503 errors from httpbin.org, we use a retry mechanism to ensure stable evaluation and submitted this fix as a PR to the official SWE-bench repository.The resolved rate is calculated as the number of resolved instances divided by the total number of instances (500).
Cheating Prevention
Recent findings (link) have exposed a vulnerability in previous SWE-Bench Docker images, which allowed agents to access future states of the repository (including commits and PRs), effectively leaking the solution. In our experiments, we observed models potentially exploiting this vulnerability by executing commands. We observed agents most commonly exploiting this vulnerability via git log –all and git show <commit_id>. Therefore, to ensure a rigorous and uncontaminated evaluation, we follow the suggestions of the SWE-Bench authors and use the recently released, patched Docker images. All experiments are conducted using the latest SWE-Bench Verified Docker images (as of September 16, 2025), which avoids this issue by preventing access to future repository history.
Case Study: Fixing Binary Payload Encoding via SAGE
In this section, we illustrate a simple case study of how an agent’s self-experienced patch attempt can later serve as the seed for plan induction—without any verifier feedback.
We structure the walkthrough as follows:
- Issue description: what went wrong in the original repository.
- Plan induction: how the agent introspected its own failure to extract a reasoning-level plan.
- SAGE patch: how that induced plan re-emerged as explicit structure in the final, correct fix.
- Takeaways: how each analysis, feedback, and new-plan element manifested in code.
Issue description (psf__requests-2931)
Sending a binary payload such as
None
requests.put(url, data=b"xc3xb6xc3xb6xc3xb6")
failed in Requests 2.9, although it worked in 2.8.1. The culprit was _encode_params, which always calledto_native_string(data) — decoding raw bytes as ASCII and triggering UnicodeDecodeError.
Goal: Preserve raw bytes exactly as sent, while still converting text types safely.
Plan induction (from self-experience, no external verifier)
After exploring the environment and self-experiencing the task through its own trial-and-error attempts, the agent transitions into an introspective phase.Rather than relying on any external signal, it analyzes its own reasoning traces. This introspection crystallizes into three reflective pillars:
(1) Analysis — What was I trying to enforce? What was my underlying plan?
(2) Feedback — What did I overlook or misunderstand during exploration?
(3) Induced Plan — How can I reframe these insights into a stronger next-step strategy?
Through this grounded self-reflection, the agent converts its raw exploration experience into a structured improvement plan, capturing both the intent behind its earlier reasoning and the adjustments needed to refine it:
🟢 Analysis
- A1. Locate where
to_native_stringis called on payloads →_encode_params. - A2. Recognize invariant: Raw binary inputs must bypass text decoding.
- A3. Hypothesize that decoding
bytesas text causes the crash. - A4. Verify that string inputs still need normalization.
🟠 Feedback
- F1. Maintain existing behavior for
strinputs(to_native_string). - F2. Broaden type coverage to prevent silent regressions (add
bytearray/memoryview). - F3. Add comment or tests capturing the “raw bytes invariant.”
- F4. Keep fix minimal and style-consistent with Requests’ codebase.
🔵 Induced Plan
- N1. Implement explicit branch for
bytes→ return unchanged. - N2. Add second branch for
str→to_native_string. - N3. Add third branch for
bytearray/memoryview→ cast tobytes. - N4. Confirm by manually testing a non-ASCII binary payload.
This induced plan distills the original intuition (“don’t decode raw bytes”) into a reproducible reasoning structure that can generalize to similar bugs.
SAGE patch with surfaced plan annotations
Once this reflective plan is induced, SAGE (Self-Augmented Guided Exploration) uses it to steer the agent’s next trajectory. Instead of re-entering the environment blindly, the agent now acts under explicit contextual scaffolds derived from its own Analysis, Feedback, and Induced Plan pillars, effectively using its own reasoning history as guidance. This transforms exploration from reactive trial-and-error into purposeful, self-guided repair, where code edits are shaped by previously surfaced insights.
The resulting patch below demonstrates how these induced planning elements materialize in code, with annotations showing which parts of the final fix stem from each reflective pillar.
None
@@ -80,8 +80,17 @@ class RequestEncodingMixin(object):
if parameters are supplied as a dict.
"""
- if isinstance(data, (str, bytes)):
- return to_native_string(data)
+ # 🟢 [Analysis] Bytes must remain untouched
+ if isinstance(data, bytes):
+ return data
+ # 🟠 [Feedback] Preserve str → native behavior
+ elif isinstance(data, str):
+ return to_native_string(data)
+ # 🔵 [New Plan] Extend to other binary containers
+ elif isinstance(data, bytearray):
+ return bytes(data)
+ elif isinstance(data, memoryview):
+ try:
+ return data.tobytes()
+ except AttributeError:
+ return data.tostring()
where the pillars of the induced plan contributed to the following improvements”
🟢 Analysis → Identified the invariant: “Raw binary data should bypass encoding.”
🟠 Feedback → Clarified type handling, preserving the legacy string path.
🔵 Induced Plan → Generalized the fix to cover all byte-like containers.
Conclusion
We introduced Plan Induction from Self-Experience, a training-free framework that enables agents to refine their performance by learning directly from their own trajectories in the environment. Through this process, agents extract and induce improved plans that guide more effective subsequent executions. Applied to realistic software engineering (SWE) tasks—specifically the SWE-Bench verified benchmark under the bash-only setting—this method yields consistent and substantial performance gains, underscoring the power of self-grounded experience as a pathway toward agents that can grow smarter and self-improve through their own interactions with the world.
Attribution
If you find this work helpful, please consider cite this in your work
@misc{sage-2025,
author = {Hiroaki Hayashi and Bo Pang and Wenting Zhao and Ye Liu and Akash Gokul and Srijan Bansal and Caiming Xiong and Semih Yavuz and Yingbo Zhou},
title = {Software Engineering Agent via Self-Abstraction from Grounded Experience},
year = {2025},
month = {Oct},
note = {Blog post, Salesforce AI Research},
howpublished = {url{salesforce.com/blog/sfr-sage-swe/}},
}References
- Panickssery, Arjun, Samuel Bowman, and Shi Feng. “Llm evaluators recognize and favor their own generations.” Advances in Neural Information Processing Systems 37 (2024): 68772-68802.
- Zheng, Lianmin, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin et al. “Judging llm-as-a-judge with mt-bench and chatbot arena.” Advances in neural information processing systems 36 (2023): 46595-46623.
- Yang, John, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. “Swe-agent: Agent-computer interfaces enable automated software engineering.” Advances in Neural Information Processing Systems 37 (2024): 50528-50652.
- Shinn, Noah, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. “Reflexion: Language agents with verbal reinforcement learning.” Advances in Neural Information Processing Systems 36 (2023): 8634-8652.
- Madaan, Aman, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon et al. “Self-refine: Iterative refinement with self-feedback.” Advances in Neural Information Processing Systems 36 (2023): 46534-46594.
- Yao, Shunyu, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. “React: Synergizing reasoning and acting in language models.” In The eleventh international conference on learning representations. 2022.
- Zhou, Andy, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. “Language Agent Tree Search Unifies Reasoning, Acting, and Planning in Language Models.” In Forty-first International Conference on Machine Learning.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}